In earlier posts I’ve described two different ways we can assess how relevant a given webpage is to a search query: (1) the cosine similarity measure; and (2) the PageRank, which is a query-independent measure of the importance of a page. While it’s good that we have multiple insights into what makes a webpage relevant, it also gives rise to a problem: how should we combine these two measures to determine the ranking of a particular webpage for a particular search query?
In fact, in practice the problem gets much more complex than this, because there are more than two useful notions of search relevance. For instance, we’d surely also wish to incorporate a relevance measure that quantifies how likely or unlikely a given page is to be spam. By doing that we could ensure that pages which are likely to be spam receive a much lower ranking. We might also wish to incorporate a measure which ranks a page based on how close together the words in the search query are on that page. Once you start to think about it, we humans combine a very large number of factors when assessing the usefulness of a webpage. This is reflected in the fact that, according to Google, their search engine combines not just two or three measures of relevance but more than 200 measures of relevance. How should we best combine all these multiple measures in order to determine how relevant a page is to a given query?
You might think that the right approach would be to think hard about the meaning of measures like cosine similarity and PageRank, and then on the basis of that understanding, to figure out optimal ways of combining those measures. This approach is certainly worth pursuing, but it suffers from a problem: it doesn’t scale very well. Even if you come up with a good way of combining cosine similarity and PageRank, how would you combine 200 different measures? It’s not so obvious. And if you decide to trial the addition of a 201st measure of relevance, how exactly should you incorporate it into your algorithm, and how should you check to see whether or not it improves search results?
In this post, I’ll describe an approach to combining multiple measures of relevance that doesn’t require us to consider the details of the individual measures. Instead, the procedure I describe lets the machine automatically learn how to combine different measures. It does this with the help of a set of training data, where humans have ranked some set of webpages according to their relevance to some set of training queries. The idea is to figure out the best way of combining the measures of relevance in order to reproduce the results of the training data. Whatever method of combination is found is then applied more broadly, to all queries, and all webpages. The big advantage of this machine learning approach is that it lets us easily combine many different notions of search relevance. But it also has some drawbacks, as we’ll see.
The post is based principally on Chapter 15 of the book about information retrieval by Manning, Raghavan, and Sch\”utze. The book is also available for free on the web.
Originally, I intended this post to be a mix of theory and working code to illustrate how the theory works in practice. This is the style I’ve used for many earlier posts, and is the style I intend to use whenever possible. However, I ran into a problem when I attempted to do that for the current post. The problem was that if I wanted to construct interesting examples (and ask interesting questions about those examples), I needed to add a lot of extra context in order for things to make sense. It would have tripled (or more) the length of an already long post. I ultimately decided the extra overhead wasn’t worth the extra insight. Instead, the post focuses on the theory. However, I have included a few pointers to libraries which make it easy to construct your own working code, if you’re so inclined. At some point I expect I’ll come back to this question, in a context where it makes much more sense to include working code.
As usual, I’ll finish the introduction with the caveat that I’m not an expert on any of this. I’m learning as I go, and there may be mistakes or misunderstandings in the post. Still, I hope the post is useful. At some point, I’ll stop adding this caveat to my posts, but I’m still a long way from being expert enough to do that! Also as per usual, the post will contain some simple exercises for the reader, some slightly harder problems, and also some problems for the author, which are things I’d like to understand better.
General approach
In this section, I’ll work through some simple hypothetical examples, using them to build up a set of heuristics about how to rank webpages. These heuristics will ultimately suggest a complete algorithm for learning how to rank webpages from a set of training data.
One small point about nomenclature: I’m going to switch from talking about “webpages” (or “pages”), and start referring instead to “documents”. In part this is because the document terminology is more standard. But it’s also because the techniques apply more broadly than the web.
To keep things simple and concrete in our hypothetical examples, we’ll assume that for any given query and document we have just two different measures of relevance, let’s say the cosine similarity and the PageRank (or some other similar measure, if we’re working with documents not from the web). We’ll call these features. And so for any given query and document pair ")
![\vec \psi(q,d) = \left[ \begin{array}{c} \mbox{PageRank}(q,d) \\ \mbox{cosine similarity}(q,d) \end{array} \right].](https://s0.wp.com/latex.php?latex=+++%5Cvec+%5Cpsi%28q%2Cd%29+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cmbox%7BPageRank%7D%28q%2Cd%29+%5C%5C++++++++%5Cmbox%7Bcosine+similarity%7D%28q%2Cd%29+%5Cend%7Barray%7D+%5Cright%5D.+&bg=ffffff&fg=000000&s=0 "\vec \psi(q,d) = \left[ \begin{array}{c} \mbox{PageRank}(q,d) \\ \mbox{cosine similarity}(q,d) \end{array} \right].")
Actually, the PageRank of a document doesn’t depend on the query 
Our broad goal can now be restated in the language of feature vectors. What we want is to find an algorithm which combines the different components of the feature vector ")

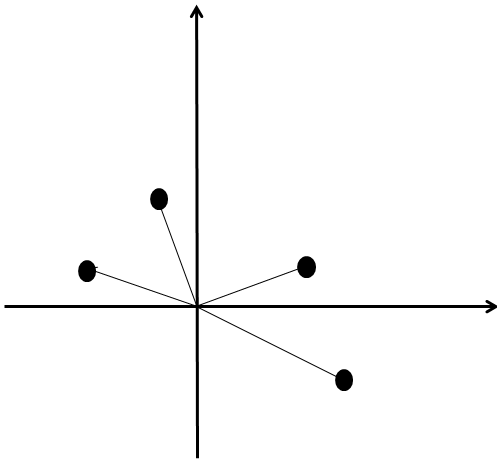
To get some insight into how we should solve this problem, let’s suppose we have an extremely simple set of training data. We’ll suppose a human operator has ranked three documents 
, \vec \psi(q,d_2), \vec \psi(q,d_3)")
")

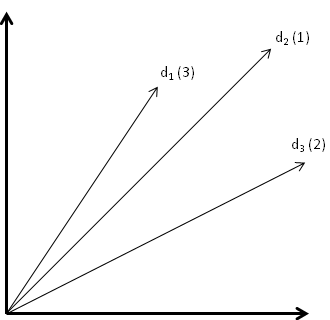
There are a few reasonable observations:
- If a feature vector
then it’s better along both axes (PageRank and cosine similarity). It seems reasonable to conclude that
.
- Coversely, if
- The hard cases are when
Note, by the way, that I don’t want to claim that that these observations are “proveable” in any way: they’re just reasonable observations, at least for the particular features (cosine similarity and PageRank) that we’re using. The idea here is simply to figure out some reasonable heuristics which we will eventually combine to suggest an algorithm for learning how to rank webpages.
With the observations above as motivation we’ll adopt the heuristic that it is the vector of feature differences  := \vec \psi(q,d)-\vec \psi(q,d')")
")

I haven’t labelled the vectors explicitly with 
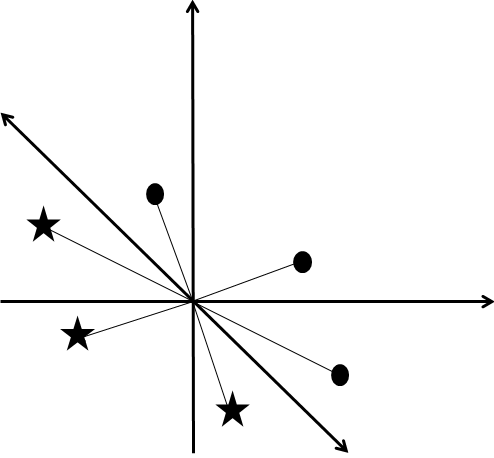
So one way we could determine whether a feature difference vector is labelled by an oval or a cross is simply by determining which half-space it is in, i.e., by determing which side of the line it’s on. Or to reformulate it in our original terms: we can tell whether a webpage
In higher-dimensional feature spaces this idea generalizes to separating the feature difference vectors into two half-spaces which are on opposite sides of a separating hyperplane. A convenient way of specifying this separating hyperplane, in any number of dimensions, is to introduce a normal vector 
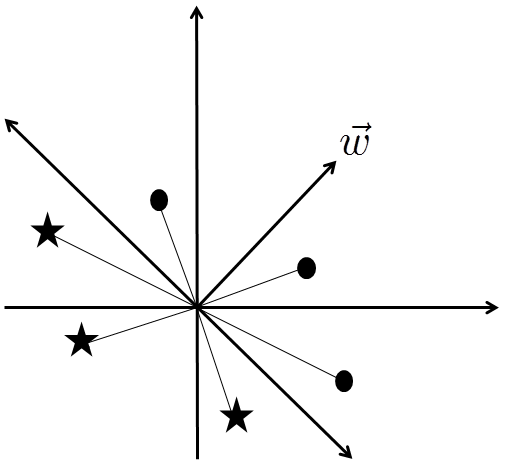
The condition for a feature difference vector to be in (say) the upper half-space is that  \cdot \vec w > 0")
![\vec \phi(q,d,d') \cdot \vec w < 0[/latex]. Summing everything up, we can check whether the document [latex]d[/latex] should be ranked above or below [latex]d'[/latex] simply by computing the sign of [latex]\vec \phi(q,d,d') \cdot \vec w[/latex]. The above observations suggest an algorithm for using the feature difference vectors to determine search relevance. It's a pretty obvious generalization of what I've just described, but at the risk of repeating myself I'll write it all out explicitly. To start, we assume that a set of training data has been provided by human operators. Those operators have been given a set of training queries [latex]q_1,q_2,\ldots,q_m[/latex] and training documents [latex]d_1,d_2,\ldots,d_n[/latex]. For each training query they've ranked each training document in order of relevance to that query. They might decide, for example, that for the query [latex]q_1[/latex], the document [latex]d_{17}[/latex] should be the top-ranked query, [latex]d_5[/latex] the second-ranked query, and so on. This training data provides us with a whole lot of feature difference vectors [latex]\vec \phi(q_i,d_j,d_k)[/latex]. These vectors can be divided up into two sets. The first set, which we'll call training data set [latex]A[/latex], contains those feature difference vectors for which [latex]d_j[/latex] has been ranked more highly than [latex]d_k[/latex]. The second set, which we'll call training data set [latex]B[/latex], contains those feature difference vectors for which [latex]d_k[/latex] has been ranked more highly than [latex]d_j[/latex]. We then find a separating hyperplane that separates these two data sets, i.e., with the <em>upper half-space</em> containing data set [latex]A](https://s0.wp.com/latex.php?latex=%5Cvec+%5Cphi%28q%2Cd%2Cd%27%29+%5Ccdot+%5Cvec+w+%3C+0%26%2391%3B%2Flatex%26%2393%3B.++Summing+everything+up%2C+we+can+check+whether+the+document+%26%2391%3Blatex%26%2393%3Bd%26%2391%3B%2Flatex%26%2393%3B+should+be+ranked+above+or+below+%26%2391%3Blatex%26%2393%3Bd%27%26%2391%3B%2Flatex%26%2393%3B+simply+by+computing+the+sign+of+%26%2391%3Blatex%26%2393%3B%5Cvec+%5Cphi%28q%2Cd%2Cd%27%29+%5Ccdot+%5Cvec+w%26%2391%3B%2Flatex%26%2393%3B.++The+above+observations+suggest+an+algorithm+for+using+the+feature+difference+vectors+to+determine+search+relevance.++It%27s+a+pretty+obvious+generalization+of+what+I%27ve+just+described%2C+but+at+the+risk+of+repeating+myself+I%27ll+write+it+all+out+explicitly.++To+start%2C+we+assume+that+a+set+of+training+data+has+been+provided+by+human+operators.++Those+operators+have+been+given+a+set+of+training+queries+%26%2391%3Blatex%26%2393%3Bq_1%2Cq_2%2C%5Cldots%2Cq_m%26%2391%3B%2Flatex%26%2393%3B+and+training+documents+%26%2391%3Blatex%26%2393%3Bd_1%2Cd_2%2C%5Cldots%2Cd_n%26%2391%3B%2Flatex%26%2393%3B.++For+each+training+query+they%27ve+ranked+each+training+document+in+order+of+relevance+to+that+query.++They+might+decide%2C+for+example%2C+that+for+the+query+%26%2391%3Blatex%26%2393%3Bq_1%26%2391%3B%2Flatex%26%2393%3B%2C+the+document+%26%2391%3Blatex%26%2393%3Bd_%7B17%7D%26%2391%3B%2Flatex%26%2393%3B+should+be+the+top-ranked+query%2C+%26%2391%3Blatex%26%2393%3Bd_5%26%2391%3B%2Flatex%26%2393%3B+the+second-ranked+query%2C+and+so+on.++This+training+data+provides+us+with+a+whole+lot+of+feature+difference+vectors+%26%2391%3Blatex%26%2393%3B%5Cvec+%5Cphi%28q_i%2Cd_j%2Cd_k%29%26%2391%3B%2Flatex%26%2393%3B.++These+vectors+can+be+divided+up+into+two+sets.++The+first+set%2C+which+we%27ll+call+training+data+set+%26%2391%3Blatex%26%2393%3BA%26%2391%3B%2Flatex%26%2393%3B%2C+contains+those+feature+difference+vectors+for+which+%26%2391%3Blatex%26%2393%3Bd_j%26%2391%3B%2Flatex%26%2393%3B+has+been+ranked+more+highly+than+%26%2391%3Blatex%26%2393%3Bd_k%26%2391%3B%2Flatex%26%2393%3B.++The+second+set%2C+which+we%27ll+call+training+data+set+%26%2391%3Blatex%26%2393%3BB%26%2391%3B%2Flatex%26%2393%3B%2C+contains+those+feature+difference+vectors+for+which+%26%2391%3Blatex%26%2393%3Bd_k%26%2391%3B%2Flatex%26%2393%3B+has+been+ranked+more+highly+than+%26%2391%3Blatex%26%2393%3Bd_j%26%2391%3B%2Flatex%26%2393%3B.++We+then+find+a+separating+hyperplane+that+separates+these+two+data+sets%2C+i.e.%2C+with+the+%3Cem%3Eupper+half-space%3C%2Fem%3E+containing+data+set+%5Blatex%5DA&bg=ffffff&fg=000000&s=0 "\vec \phi(q,d,d') \cdot \vec w < 0[/latex]. Summing everything up, we can check whether the document [latex]d[/latex] should be ranked above or below [latex]d'[/latex] simply by computing the sign of [latex]\vec \phi(q,d,d') \cdot \vec w[/latex]. The above observations suggest an algorithm for using the feature difference vectors to determine search relevance. It's a pretty obvious generalization of what I've just described, but at the risk of repeating myself I'll write it all out explicitly. To start, we assume that a set of training data has been provided by human operators. Those operators have been given a set of training queries [latex]q_1,q_2,\ldots,q_m[/latex] and training documents [latex]d_1,d_2,\ldots,d_n[/latex]. For each training query they've ranked each training document in order of relevance to that query. They might decide, for example, that for the query [latex]q_1[/latex], the document [latex]d_{17}[/latex] should be the top-ranked query, [latex]d_5[/latex] the second-ranked query, and so on. This training data provides us with a whole lot of feature difference vectors [latex]\vec \phi(q_i,d_j,d_k)[/latex]. These vectors can be divided up into two sets. The first set, which we'll call training data set [latex]A[/latex], contains those feature difference vectors for which [latex]d_j[/latex] has been ranked more highly than [latex]d_k[/latex]. The second set, which we'll call training data set [latex]B[/latex], contains those feature difference vectors for which [latex]d_k[/latex] has been ranked more highly than [latex]d_j[/latex]. We then find a separating hyperplane that separates these two data sets, i.e., with the <em>upper half-space</em> containing data set [latex]A")



Suppose now that
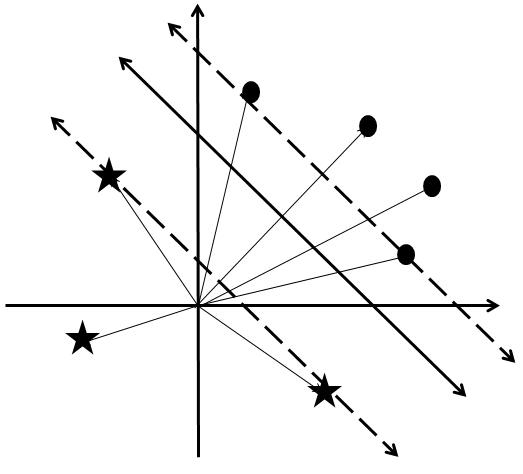
There are many problems with this basic algorithm. One problem becomes evident by going back to our primitive training data and adding an extra document:
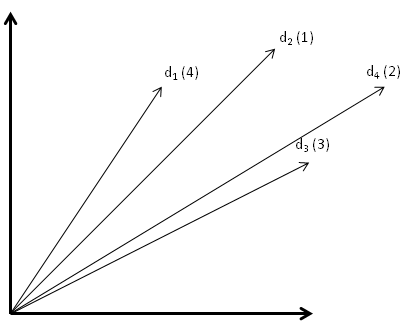
Inspecting the feature difference vectors reveals a problem:
I’ve simplified the picture by showing only the feature difference vectors ")

Before getting to the approximate division, though, we’ll warm up by figuring out much more explicitly how to do the division into two half-spaces when it is possible. It’s all very well for me to glibly say that we should “figure out which half-space the vector
Problems
- Suppose the basic algorithm that I’ve described works, i.e., a division into half-spaces is possible. Suppose that for a particular query
. Prove that the algorithm will rank
Support vector machines
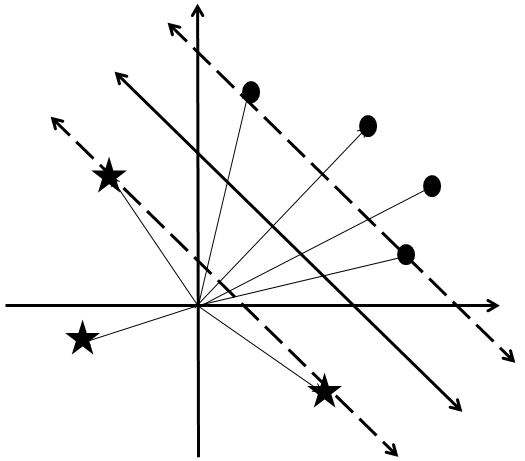
Support vector machines are a technique for partitioning two sets of vectors (data set
As an aside, you’ll note that the notion of search (and related topics) wasn’t mentioned anywhere in the last paragraph. That’s because support vector machines aren’t about search. Instead, they’re a general technique for dividing sets of vectors into half-spaces, a technique which can be applied to many different problems in machine learning and artificial intelligence, not just search. So support vector machines are a useful technique to understand, even if you’re not especially interested in search. End of aside.
A priori if someone just gives you two sets of vectors,

Note that in the last section our separating hyperplanes passed through the origin. But for support vector machines we’ll also allow hyperplanes which don’t pass through the origin. One way to explicitly specify such a hyperplane is as the set of vectors 

where 
where we require that the two edges of the wedge (called support or supporting hyperplanes) be parallel to the separating hyperplane itself. In other words, the goal is to choose the separating hyperplane (i.e., to choose
Let me mention, by the way, that I’m not mad keen on the notations we’ve been using, such as 

Let’s get back to the problem of choosing
Let’s fix our attention on one of the two supporting hyperplanes, say, the one that is “higher up” in the picture above. We’ll suppose, also without any loss of generality, that this is the hyperplane supporting data set

and so the constraint that this hyperplane support data set 
Exercises
- If you’re not comfortable with hyperplanes you may not immediately see why the kind of rescaling of
We can now determine the distance between the supporting and separating hyperplane by introducing a vector 


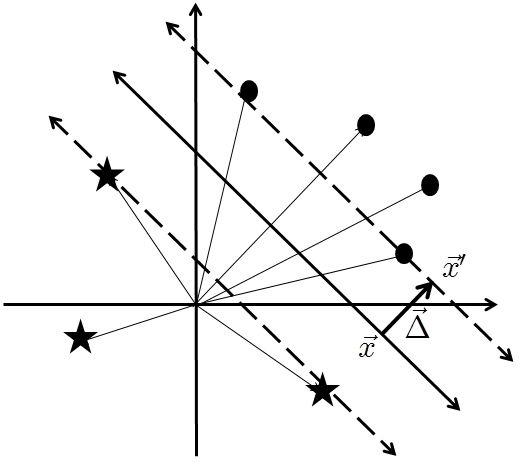
Our goal is to find the length of 






We chose the separating hyperplane to be halfway between the two supporting hyperplanes, and so the total size of the wedge is 




for all the vectors
Exercises
- Prove that
is the equation for the supporting hyperplane for data set
There is a reasonably nice way of combining the two sets of constraint inequalities for data sets 

 \geq 1,")
with equality holding if the vector in question is on a supporting hyperlane (a so-called support vector). This single set of inequalities represents the constraint that
Rather than maximize 
Summing up, our problem is to find

subject to the constraints
where
This formulation of our problem represents real progress. The reason is that the problem just described is an instance of a very well-known type of problem in mathematics and computer science, called a quadratic programming problem. Although quadratic programs don’t in general have simple, closed-form solutions, they’ve been studied for decades and are well understood, and there are good algorithms and libraries for solving them. It’s because quadratic programs are so well understood that we changed from maximizing 

Incidentally, one potentially confusing thing about the quadratic programming problem posed above – and one of the reasons I complain about the notation – is to be clear on exactly what is being solved for. The 


We can now explain what a support vector machine actually is. We have some problem – like the search ranking problem – which generate sets of training data, 
![\vec w \cdot \vec x + b < 0[/latex]. A support vector machine is an example of a <a href="http://en.wikipedia.org/wiki/Linear_classifier">linear classifier</a>: a decision procedure which makes a classification decision (``Is page [latex]d](https://s0.wp.com/latex.php?latex=%5Cvec+w+%5Ccdot+%5Cvec+x+%2B+b+%3C+0%26%2391%3B%2Flatex%26%2393%3B.++A+support+vector+machine+is+an+example+of+a+%3Ca+href%3D%22http%3A%2F%2Fen.wikipedia.org%2Fwiki%2FLinear_classifier%22%3Elinear+++classifier%3C%2Fa%3E%3A+a+decision+procedure+which+makes+a+classification+decision+%28%60%60Is+page+%5Blatex%5Dd&bg=ffffff&fg=000000&s=0 "\vec w \cdot \vec x + b < 0[/latex]. A support vector machine is an example of a <a href=\"http://en.wikipedia.org/wiki/Linear_classifier\">linear classifier</a>: a decision procedure which makes a classification decision (``Is page [latex]d")
I won’t go any deeper into the theory or practice of support vector machines in this post. Instead, we’ll return to the question of how to deal with the fact that sometimes it’s not possible to separate the training data into two half-spaces. What we’ll see is that it is possible to do an approximate separation, using the same techniques of quadratic programming. This is known as a support vector machine with a soft margin. Once we’ve understood how that works I’ll come back to what this all means in the context of search.
Support vector machines with a soft margin
In our earlier discussion of search, we saw an example where the feature difference vectors in a set of training data cannot be partitioned into two half-spaces (again, as earlier, this diagram only shows feature difference vectors
What can we do in this situation? There is a way of modifying the support vector machine idea to find an approximate way of partitioning two sets of vectors into half-spaces. The idea is to allow some of the vectors to slightly violate the half-space constraints. We compensate for these violations by paying a penalty in the function being minimized. This will ensure that any violations are quite small.
The way this idea is implemented is as follows. We introduce some slack variables 
 \geq 1-\xi_j.")
We also impose the constraint on the slack variables that

simply so as to ensure that we’re not over-constraining our vectors by picking a negative value for

Here 
The problem defined in the last paragraph is (again) a quadratic program, and standard algorithms and libraries can be used to solve the program. Also as in the last section, given a solution to the program we can use that solution as a binary linear classifier. In particular, suppose ![\vec w \cdot \vec x + b < 0[/latex]. An issue that I haven't addressed - and don't yet know how to solve - is how to choose the soft margin parameter, [latex]C[/latex]. As a starting point for understanding this choice, let me at least state the following: <strong>Theorem:</strong> A solution to the quadratic program above always exists. This is a major improvement over the situation without the soft margin, where it's not even guaranteed that a solution will exist. It means that no matter what the training data or soft margin parameter, we can always build a binary linear classifier using the support vector machine with that soft margin. I won't give the proof of the theorem, but the intuition is simple enough: for any choice of [latex]\vec w](https://s0.wp.com/latex.php?latex=%5Cvec+w+%5Ccdot+%5Cvec+x+%2B+b+%3C+0%26%2391%3B%2Flatex%26%2393%3B.++An+issue+that+I+haven%27t+addressed+-+and+don%27t+yet+know+how+to+solve+-+is+how+to+choose+the+soft+margin+parameter%2C+%26%2391%3Blatex%26%2393%3BC%26%2391%3B%2Flatex%26%2393%3B.++As+a+starting+point+for+understanding+this+choice%2C+let+me+at+least+state+the+following%3A++%3Cstrong%3ETheorem%3A%3C%2Fstrong%3E+A+solution+to+the+quadratic+program+above+always+exists.+++This+is+a+major+improvement+over+the+situation+without+the+soft+margin%2C+where+it%27s+not+even+guaranteed+that+a+solution+will+exist.++It+means+that+no+matter+what+the+training+data+or+soft+margin+parameter%2C+we+can+always+build+a+binary+linear+classifier+using+the+support+vector+machine+with+that+soft+margin.+++++I+won%27t+give+the+proof+of+the+theorem%2C+but+the+intuition+is+simple+enough%3A+for+any+choice+of+%5Blatex%5D%5Cvec+w&bg=ffffff&fg=000000&s=0 "\vec w \cdot \vec x + b < 0[/latex]. An issue that I haven't addressed - and don't yet know how to solve - is how to choose the soft margin parameter, [latex]C[/latex]. As a starting point for understanding this choice, let me at least state the following: <strong>Theorem:</strong> A solution to the quadratic program above always exists. This is a major improvement over the situation without the soft margin, where it's not even guaranteed that a solution will exist. It means that no matter what the training data or soft margin parameter, we can always build a binary linear classifier using the support vector machine with that soft margin. I won't give the proof of the theorem, but the intuition is simple enough: for any choice of [latex]\vec w")
While the theorem above is an encouraging start, it’s not what we really want. What we’d like is to understand how best to choose
Problems
- Above, I talked about the soft margin parameter
- Suppose the data sets have the property that data set
in
. In fact, it’s possible to prove (though we won’t do so) that the solution to the quadratic program is unique, and so we must have
, and therefore
. It follows that for the search problem we can assume
Problems for the author
- The modifications to the support vector machine model made in this section are quite ad hoc. In particular, choosing the penalty to be
seems to me to be quite unmotivated. Is there some natural geometric way of deriving this model? Even better, is there a principled way of deriving the model?
Search revisited
Let’s return to the problem of search. As we saw in the last section, we can use training data to build a support vector machine (with soft margin) that, given a query,
Problems
- Suppose that the relevancy ranking algorithm just described ranks the document
How can we use this support vector machine in practice? One way is as follows. Suppose we have 
")
This approach isn’t really the best, though. Suppose, for comparison, that you had 
")
Of course, we can apply the same idea with our support vector machine. Simply do a single pass over all
Quite aside from being significantly faster than ranking all documents, a major advantage of the running tally method is that it is easily run on a large cluster. Each machine simply computes the top
This post has introduced a simple technique which can be used to combine different notions of search relevancy. It’s very much an introduction, and there are a huge number of problems I have not addressed. Perhaps the biggest one is this: how well does this procedure work in practice? That is, does it give a satisfying search experience, one which is significantly improved by the addition of new relevancy factors? I’d love to test this out, but I don’t have good enough trial data (yet) to do a really good test. Maybe someone can point to some real data along these lines.
At this point in the original drafting of this post, I began enumerating problems one might want to think about in applying these ideas to improve a real search engine. The list quickly became very long: there’s a lot to think about! So rather than list all those problems, I’ll conclude with just a couple of problems which you may ponder. Enjoy!
Problems for the author
- Suppose we’re running a real-life search engine, and were thinking of introducing an additional feature. How could we use A/B testing to determine whether or not that additional feature does a little or a lot to help improve relevancy ranking?
- At the beginning of this post I proposed figuring out (by thinking hard!) a principled way of combining cosine similarity and PageRank to come up with a composite measure of relevance. Find such a principled way of making the combination. I expect that the value in attacking this problem will lie not so much in whatever explicit combination I find, but rather in better understanding how to make such combinations. It may also shed some light on when we expect the machine learning approach to work well, and when we’d expect it to work poorly.
Interested in more? Please follow me on Twitter. You may also enjoy reading my new book about open science, Reinventing Discovery.
Since you asked for trial data, here’s the website of the 2010 yahoo learning to rank challenge:
http://learningtorankchallenge.yahoo.com/
The datasets are quite big and are said to come from a real web search engine :). Unfortunately no description of the features (>500) is provided.
http://research.microsoft.com/en-us/projects/mslr/default.aspx
Microsoft even shared a description of the features.
Skimming your article only, i wondered how you combine the SVM-scores into an explicit ranking? I played around with pairwise ranking myself and decided to sum the scores for the n(n -1) / 2 pairs. Which works okish, but is still an ugly heuristic…
Thanks for the pointers, I’ll take a look!
As regards your explicit ranking question, take a look at the next post, which is quite a bit clearer on this question.